Compiler Engine Overview#
A picture is 1000 words! The figure below shows how the PolyBlocks compiler works and how its compiler engine is layered using MLIR and LLVM. Please take a look at the MLIR documentation for an introduction to the notions of MLIR dialects, passes, conversions, and transformations.
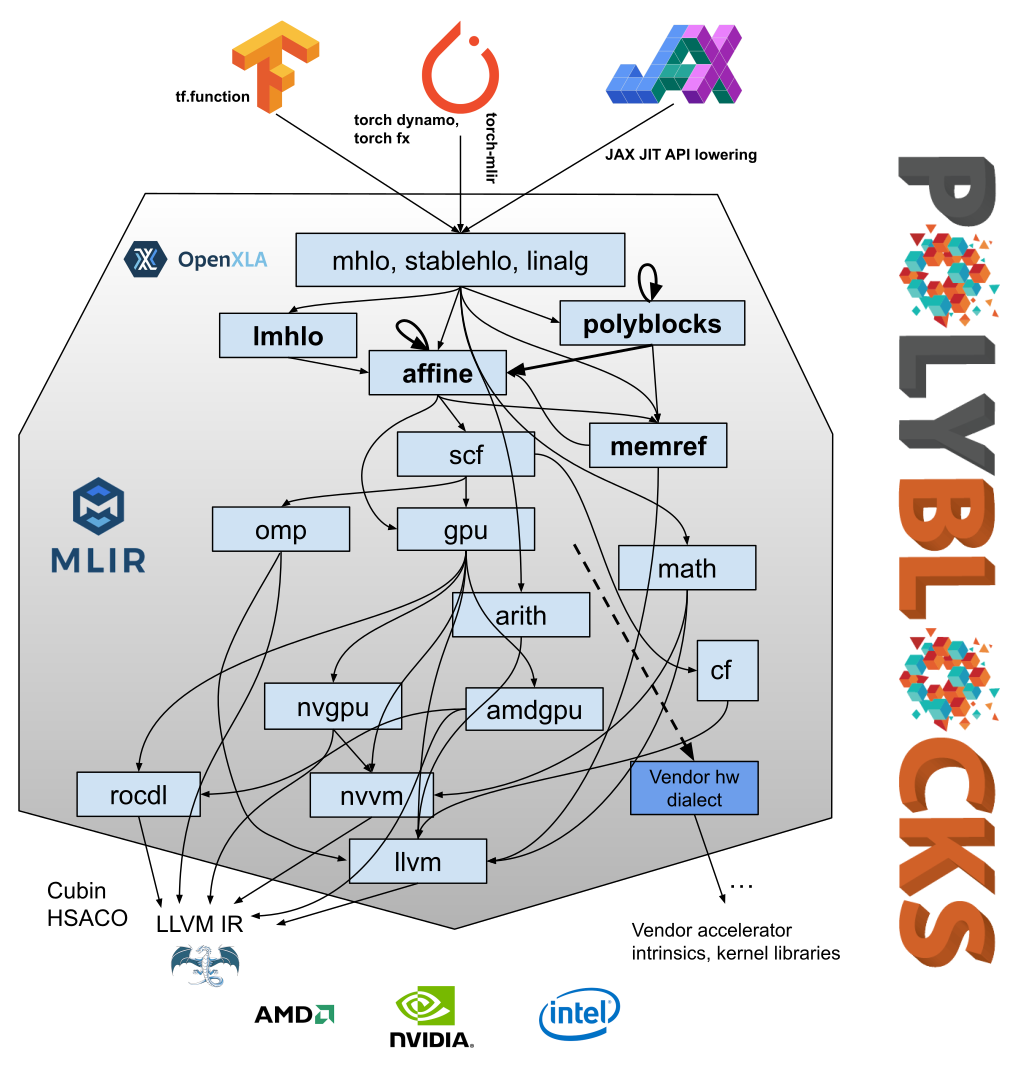
The PolyBlocks compiler engine can be viewed as an MLIR-based pass pipeline with 150+ passes that transform and optimize IR through various stages. It mainly employs polyhedral optimization techniques in the mid-level stages while optimizing computations on high-dimensional data spaces. The optimization techniques encompass tiling, fusion, performing recomputation (in conjunction with tiling and fusion), packing into on-chip buffers for locality, eliminating intermediate tensors or shrining intermediate tensors to bounded buffers fitting into on-chip memory, mapping to matmul/tensor cores, and efficient parallelization in a way that is unified with all other transformations. Several MLIR’s upstream passes are also used in our code generation pipeline.
PolyBlocks is fully automatic, analytical model-driven, and 100% code generating, i.e., it does not rely on vendor libraries. Unlike a few other approaches to domain-specific compilation, PolyBlocks does not use “named” operator-wise scheduling/transformation recipes or hand-crafted schedules. Instead, all IR is processed by the same pass pipeline. Information on the structure of the operators is still exploited at appropriate levels, but in a general way using “PolyBlocks” kinds and affine structures in the IR.